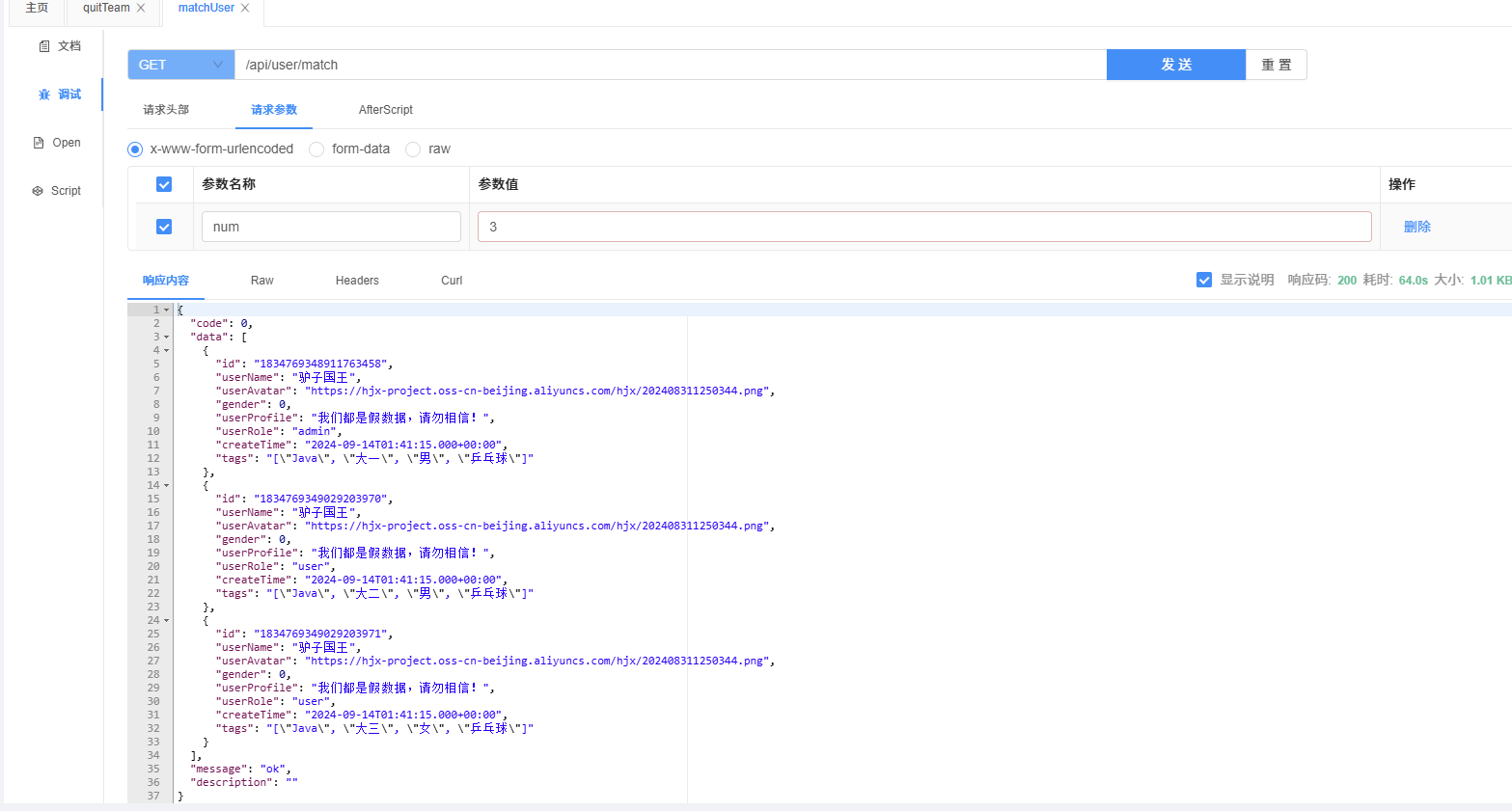
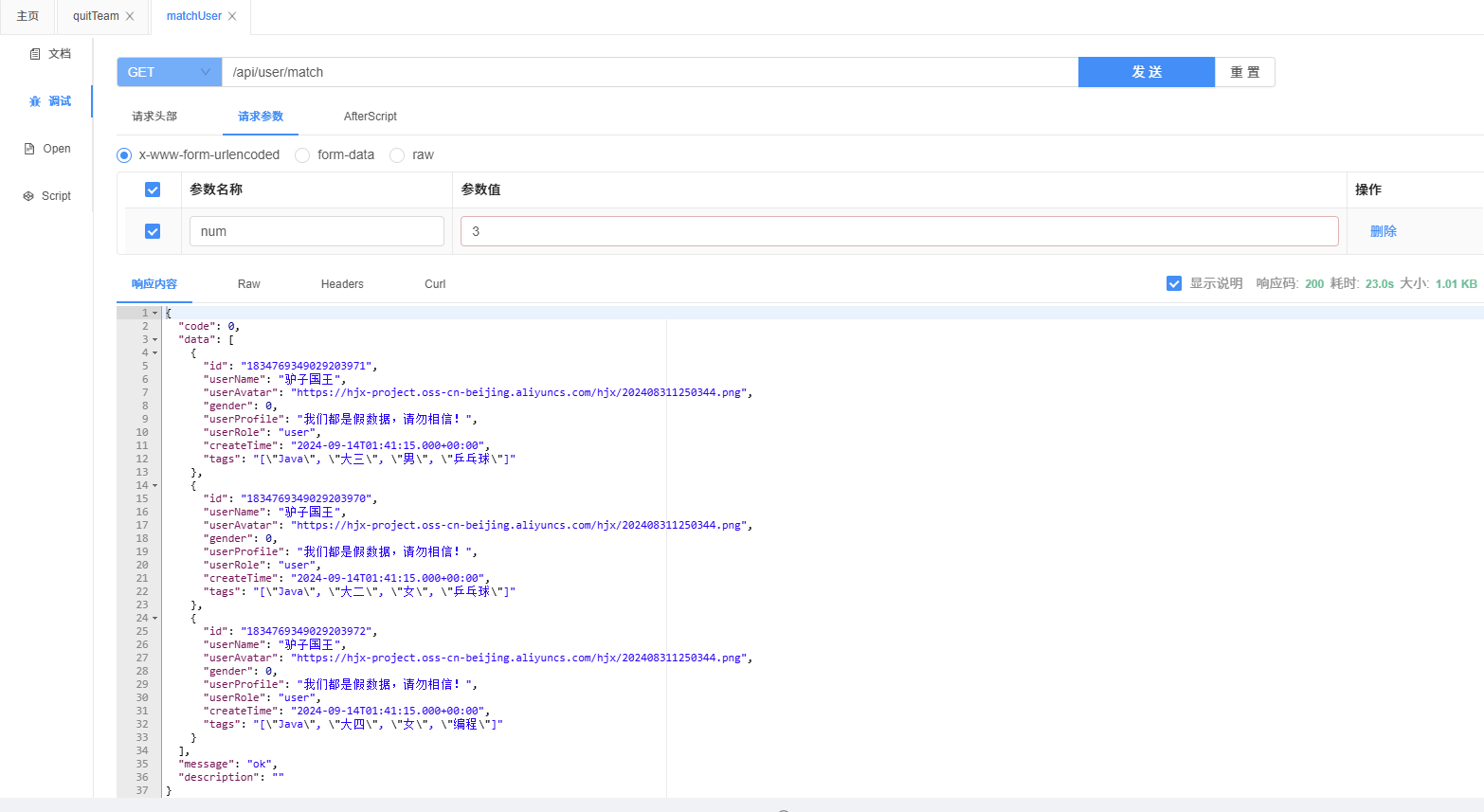
@Override
public List<UserVO> matchUser(long num, User loginUser) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
// 只查询有标签的用户
queryWrapper.isNotNull("tags");
queryWrapper.select("id", "tags");
List<User> userList = this.list(queryWrapper);
// 序列化登录用户的标签
String loginUserTags = loginUser.getTags();
Gson gson = new Gson();
List<String> tagList = gson.fromJson(loginUserTags, new TypeToken<List<String>>() {
}.getType());
// 用户列表的下标 => 相似度
List<Pair<User, Long>> list = new ArrayList<>();
// 依次计算当前用户和所有用户的相似度
for (int i = 0; i < userList.size(); i++) {
User user = userList.get(i);
String userTags = user.getTags();
//无标签的 或当前用户为自己
if (StringUtils.isBlank(userTags) || Objects.equals(user.getId(), loginUser.getId())) {
continue;
}
List<String> userTagList = gson.fromJson(userTags, new TypeToken<List<String>>() {
}.getType());
//计算分数
long distance = AlgorithmUtils.minDistance(tagList, userTagList);
list.add(new ImmutablePair<>(user, distance));
}
// 按编辑距离由小到大排序
List<Pair<User, Long>> topUserPairList = list.stream()
.sorted((a, b) -> (int) (a.getValue() - b.getValue()))
.limit(num)
.toList();
// 有顺序的userID列表
List<Long> userIdList = topUserPairList.stream().map(pari -> pari.getKey().getId()).toList();
//根据id查询user完整信息
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
userQueryWrapper.in("id", userIdList);
Map<Long, List<UserVO>> userIdUserListMap = this.list(userQueryWrapper).stream()
.map(this::getUserVO)
.collect(Collectors.groupingBy(UserVO::getId));
// 因为上面查询打乱了顺序,这里根据上面有序的userID列表赋值
List<UserVO> finalUserListVO = new ArrayList<>();
for (Long userId : userIdList) {
finalUserListVO.add(userIdUserListMap.get(userId).getFirst());
}
return finalUserListVO;
}